Kubernetes, debezium and Kafka
From a shine new Kafka cluster to Postgres streaming - in minutes

In this article i want to show
- how easy it is to deploy a kafka cluster on kubernetes
- how to deploy kafka connect with debezium connector streaming postgres events to kafka
For the Kafka deployment, I going to be using Strimzi. Strimzi is a helm chart that incorporates some Kafka resources on your k8s cluster. For example, kafka itself, zookeeper, kafka connect, kafka bridge and etc.
This means that, when deploying a new artifact you could simply use kind: Kafka in YAML definition, take a look below:
kafka_cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 1
logging:
type: inline
loggers:
kafka.root.logger.level: "DEBUG"
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: scram-sha-512
- name: external
port: 9094
type: ingress
tls: true
authentication:
type: scram-sha-512
configuration:
class: nginx
bootstrap:
host: bootstrap.192.168.15.160.nip.io
brokers:
- broker: 0
host: broker-0.192.168.15.160.nip.io
resources:
requests:
memory: 2Gi
cpu: 500m
limits:
memory: 2Gi
cpu: 1000m
jvmOptions:
-Xms: 800m
-Xmx: 900m
authorization:
type: simple
storage:
deleteClaim: true
size: 10Gi
type: persistent-claim
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
log.message.format.version: "2.1"
zookeeper:
replicas: 1
jvmOptions:
-Xms: 256m
-Xmx: 256m
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
resources:
requests:
memory: 384Mi
cpu: 200m
limits:
memory: 384Mi
cpu: 1000m
entityOperator:
topicOperator: {}
userOperator: {}
kafka_user.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaUser
metadata:
name: my-user
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: scram-sha-512
authorization:
type: simple
acls:
- resource:
type: topic
name: '*'
patternType: literal
operation: All
- resource:
type: group
name: connect-cluster
patternType: literal
operation: All
To enable Strimzi on k8s cluster, first we need to install it through helm install:
helm upgrade --install kafka-release strimzi/strimzi-kafka-operator --namespace kafka --create-namespace
Then we can proceed and install the artifacts above:
kubectl apply -f kafka_cluster.yaml -n kafka
kubectl apply -f kafka_user.yaml -n kafka
After a few minutes, you should see something like below:
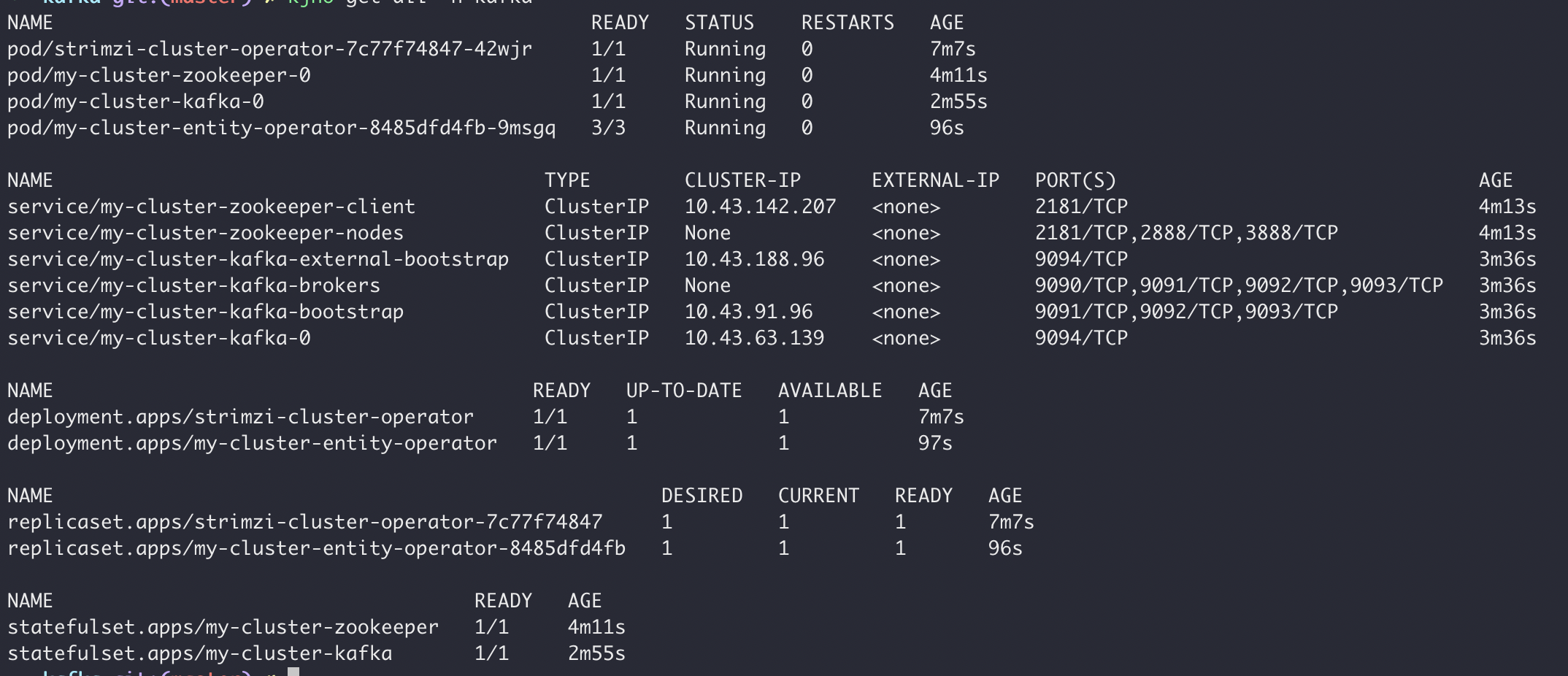
To be able to access the cluster, we need to get the server certificate and get the user password. This will depend upon what authentication type you choose for your service endpoint. Take a look here to see all available options Strimzi offers.
kubectl get secret my-user -o jsonpath='{.data.password}' -n kafka | base64 --decode
kubectl get secret my-cluster-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' -n kafka | base64 -d > ca.crt
You can test the access listing the cluster topics. Here I'm using kafkacat cli to interact with my cluster.
kcat -L -b bootstrap.192.168.15.160.nip.io:443 -X security.protocol=SASL_SSL -X ssl.ca.location="ca.crt" -X sasl.mechanisms=SCRAM-SHA-512 -X sasl.username="my-user" -X sasl.password="eUy5FoyEUNht"
Kafka Connect
To be able to use debezium we need to first enable Kafka Connect in our cluster. Kafka Connect is a tool that helps ingest and extract data to-from Kafka using connectors. Connectors are plugins that provide the connection configuration needed. There are two types of connectors, the sources to ingest and a sink to extract.
In the yaml below, I'm informing Strimzi to build the final image with debezium inside. When deploying the final pod, it will use that image.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
annotations:
strimzi.io/use-connector-resources: "true"
spec:
version: 3.2.0
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
authentication:
type: scram-sha-512
username: my-user
passwordSecret:
secretName: my-user
password: password
config:
group.id: connect-cluster
replication.factor: 1
default.replication.factor: 1
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
offset-syncs.topic.replication.factor: 1
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
resources:
requests:
memory: 1Gi
cpu: 500m
limits:
memory: 1Gi
cpu: 1000m
jvmOptions:
-Xms: 256m
-Xmx: 256m
build:
output:
type: docker
image: kleinkauff/my-connect-cluster:latest
pushSecret: docker-hub-secret
plugins:
- name: debezium-postgres-connector
artifacts:
- type: zip
url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.4.2.Final/debezium-connector-postgres-1.4.2.Final-plugin.zip
sha512sum: -
template:
pod:
securityContext:
runAsUser: 0
Debezium
In debezium configuration we have to tell how the connector should connect to our database and also, the slot that it should create and use. In table.include.list attribute you could tell the connector to track just specific tables, by default every table you create will have a correspondent Kafka topic.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-debezium-connector-jhodb
labels:
strimzi.io/cluster: my-connect
spec:
class: io.debezium.connector.postgresql.PostgresConnector
tasksMax: 1
config:
database.hostname: jhodb-postgres-chart.jhodb
database.port: 5432
database.user: postgres
database.password: super_pwd
database.dbname: jhodb
database.server.name: jhodb-debezium
slot.name: slot_debezium
plugin.name: pgoutput
decimal.handling.mode: double
Go to your database and check the replication slots:

If you can see the replication slot, this mean debezium is working as expected. Of course, some integration errors could happen, but the connector can see your database and Kafka.
Create a table and insert something into it.
jhodb=# create table debezium_events (id int primary key, name varchar(50));
jhodb=# insert into debezium_events values (1, 'dummy event');
jhodb=# insert into debezium_events values (2, 'dummy event 2');
jhodb=# insert into debezium_events values (3, 'dummy event 3');
jhodb=# delete from debezium_events where id = 2;
jhodb=# update debezium_events set name = 'dummy event updated' where id = 3;
debezium should create a topic for the new table in the following format:
{database.server.name}.{table.schema}.{table.name}
When i query kafka for the topic jhodb-debezium.public.debezium_events, here's the result:
insert 1
{
"before":null,
"after":{
"id":1,
"name":"dummy event"
},
"source":{
"version":"1.4.2.Final",
"connector":"postgresql",
"name":"jhodb-debezium",
"ts_ms":1658856811494,
"snapshot":"false",
"db":"jhodb",
"schema":"public",
"table":"debezium_events",
"txId":780,
"lsn":117760992,
"xmin":null
},
"op":"c",
"ts_ms":1658856812045,
"transaction":null
}
insert 2
{
"before":null,
"after":{
"id":2,
"name":"dummy event 2"
},
"source":{
"version":"1.4.2.Final",
"connector":"postgresql",
"name":"jhodb-debezium",
"ts_ms":1658856819364,
"snapshot":"false",
"db":"jhodb",
"schema":"public",
"table":"debezium_events",
"txId":781,
"lsn":117761328,
"xmin":null
},
"op":"c",
"ts_ms":1658856819684,
"transaction":null
}
insert 3
{
"before":null,
"after":{
"id":3,
"name":"dummy event 3"
},
"source":{
"version":"1.4.2.Final",
"connector":"postgresql",
"name":"jhodb-debezium",
"ts_ms":1658856833219,
"snapshot":"false",
"db":"jhodb",
"schema":"public",
"table":"debezium_events",
"txId":782,
"lsn":117761576,
"xmin":null
},
"op":"c",
"ts_ms":1658856833419,
"transaction":null
}
delete of #2
{
"before":{
"id":2,
"name":null
},
"after":null,
"source":{
"version":"1.4.2.Final",
"connector":"postgresql",
"name":"jhodb-debezium",
"ts_ms":1658856857204,
"snapshot":"false",
"db":"jhodb",
"schema":"public",
"table":"debezium_events",
"txId":783,
"lsn":117761824,
"xmin":null
},
"op":"d",
"ts_ms":1658856857367,
"transaction":null
}
update of #3
{
"before":{
"id":3,
"name":"dummy event updated"
},
"after":{
"id":3,
"name":"dumy"
},
"source":{
"version":"1.4.2.Final",
"connector":"postgresql",
"name":"jhodb-debezium",
"ts_ms":1658873058111,
"snapshot":"false",
"db":"jhodb",
"schema":"public",
"table":"debezium_events",
"txId":788,
"lsn":117769416,
"xmin":null
},
"op":"u",
"ts_ms":1658873058550,
"transaction":null
}
}
When doing an update, debezium will fill the "before" field only if table option REPLICA IDENTITY equals to FULL.
ALTER TABLE debezium_events REPLICA IDENTITY FULL;
Hope this guide sparks some curiosity in you. Thanks for reading.